

SVM (Support Vector Machine)
It is a classification method. In this algorithm, we plot each data item as a point in n-dimensional space (where n is number of features you have) with the value
of each feature being the value of a particular coordinate.
For example, if we only had two features like Height and Hair length of an individual, we’d first plot these two variables in two dimensional space where each point
has two co-ordinates (these co-ordinates are known as Support Vectors)

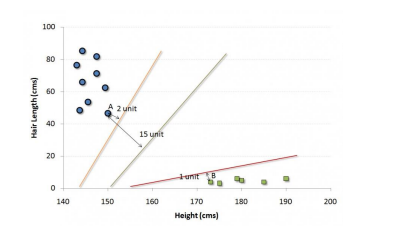
In the example shown above, the line which splits the data into two differently classified groups is the black line, since the two closest points are the farthest apart
from the line. This line is our classifier. Then, depending on where the testing data lands on either side of the line, that’s what class we can classify the new data
as.
Example in Python for Support Vector Machine
0 Comments